1. Abstract
Open data, published by public and private organizations, have a huge potential in the data-driven society for sustaining scientific knowledge sharing and product and service development, and for addressing economic and political issues, such as the measurement of impact of policies. However, many promises of open data are still unfulfilled, and many barriers of different types, e.g., social, economic, organizational, and technical, exist in publishing and using open data [32]. In this project we concentrate on the technical issues hampering the exploitation of open data, that are among the major obstacles to the spreading and usage of open data [1,2]. In particular, the 2017 global report of the Open Data Barometer [3] claims that the diffusion and usage of open data is hampered by the lack of:
appropriate data management policies,
well-structured automated procedures for data publishing,
disciplines in the definition and usage of metadata,
strong and formalized policy foundations that articulate appropriate privacy and data protection safeguards,
methods for increasing user friendliness in the access to data,
technical and organisational reforms needed to improve open data’s impact in the social system.
Consider the career center of a university facing the problem of publishing open data about student careers. Some Italian universities publish summary data, e.g. a CSV file with the number of graduations by school, including few characteristics of students (see, for example, [38]). Very poor metadata are associated with the dataset, whose meaning is therefore not exposed in a machine-readable form. Analogously, data quality (e.g., completeness or accuracy) is impossible to access. From this observation, we can infer that the process for publishing such dataset is most likely manual and ad hoc, with no help from tools and methods. Thus, the effort to produce the dataset cannot be reused for other goals, and a new information need will result in the same kind of costly process. Also, the published data is far from constituting a valuable asset for understanding student careers. A much more meaningful set of data would present individual careers, with the sequence of exams, their date and grade, perhaps with a variety of information about the provenance of the individual, such as her educational, economic, and social background, but with no personal information. The university may fear the risk of illegally publishing open data against privacy, but it could publish much more useful data with a well-informed publication process, assisted by tools, and aware of real impediments in exposing private data.
Very few portals (in Italy and abroad) publish well organized open data. One of them is Camera di Commercio in Camerino, publishing open data about foreigners working in Italy, aggregated by country of origin and by Italian region/province, which are fully accessible, and ready-to-use, although with no semantic annotation. These data reveal that foreign workers in Lombardy have decreased to 134K in 2017, after rising to 142K in 2016, thus going back to the same number of workers as in March 2014, Interestingly, in spite of this data, the lack of work for Italians due to the increase in foreigners was widely used as a political argument in Lombardy during 2017. With the results of HOPE, we will enable administrations to publish annotated open data of comparable high quality.
Our starting point in this project is that, as the above observations show, although IT research has devoted efforts to defining platforms and architectures for publishing open data, what is still missing is a formal and comprehensive methodology supporting an organization in (i) deciding which data to publish so that privacy requirements are met, (ii) carrying out precise procedures for the automatic production of semantically annotated, high-quality data, (iii) providing both powerful, and user-friendly mechanisms for expressing queries over open data, (iv) enriching open data with suitable information so as to meaningfully situate them in the social ecosystem. Overcoming these technical difficulties is exactly the goal of HOPE. The main result will be a novel semantic open data management system that an organization can use for governing the whole lifecycle of its open data, and the final users can access for effectively consuming the information provided by the organization.
The project puts together 5 partners including the strongest leaders of the Italian Knowledge Representation and Data Management communities. It is organized in 7 workpackages, 6 of them addressing the above mentioned challenges, and one devoted to coordination, integration, and experimentation. Three Italian Public Administration institutions will collaborate in order to experiment the methods and the tools developed within the project.
2. Detailed description of the project: targets that the project aims to achieve and their significance in terms of advancement of knowledge, state of the art and proposed methodology
Main objective
The grand objective of HOPE is to overcome the main technical problems and limitations that current open data solutions suffer from, and develop a methodology and associated tools for a new way of producing, publishing, maintaining, accessing and exploiting privacy-preserving open data. The envisioned result of the project is a complete web-based semantic open data management system, called HOPES, that an organization can use for governing the whole lifecycle of its open data, and the final users can access for effectively consuming the information provided by the organization.
The main pillar of HOPE is the Ontology-based Data Management (OBDM) [19] paradigm as a basis of a new architecture for managing open data. OBDM conceives a data-intensive system as constituted by three layers: the ontology, the data sources, and the mapping between the two. The source layer represents the existing resources storing the data that are relevant for the organization. The ontology is an explicit representation of the domain of interest, specified by means of a logical description. The form of the ontology is instrumental for enabling additional properties to be inferred, by logical reasoning. The mapping is a set of declarative assertions specifying how the available sources in the data layer relate to the ontology. With this approach, the integrated view over the underlying data is a semantically rich description of the relevant concepts and relationships in the domain of interest, as well as the connection between the concrete data items and the domain descriptions. The users express their needs (e.g., a query) in the terms of the concepts and the relations described in the ontology, and is then freed from the details of how the data are stored and used at the sources. The system reasons about the ontology and the mappings, and reformulates the needs in terms of appropriate calls to services provided for accessing the data sources. In order to translate the queries expressed over the ontology into correct and efficient computations over the data sources, techniques typical of Knowledge Representation and Automated Reasoning are crucial. The OBDM paradigm was proposed and pioneered by two groups participating in this project [11], and has been successfully applied in several scenarios (see, e.g., [4]). This project aims at leveraging it for a novel approach to open data management, based on the following observations.
A necessary prerequisite for an organization for publishing relevant and meaningful data is to be able to manage, maintain, and document its own information system, which is exactly the goal of OBDM.
The OBDM paradigm promotes a new way of automatically producing high-quality, semantically annotated open data without (or, with little) manual intervention.
The formal nature of an OBDM specification leads to a new way of declaratively specifying the privacy policy that the organization wants to follow in publishing open data. The system can then use the ODBM reasoning capabilities in order to ensure that the open data exposed to the consumers conform to the decision taken by the organization about its privacy policies.
The availability of the ontology and the semantic annotation of the exposed data has several advantages for the consumer, including the possibility of using a question answering system for extracting information from the open datasets, and the possibility of both enriching datasets with related content from interesting media and of situating the datasets in the social environment.
Challenges and state of the art
In order to achieve the grand objective of the project, HOPES should provide a plethora of services, both for the provider of open data, and for the consumer, and each of them introduces new research challenges that we address in the project.
From the point of view of the providers, HOPE aims at delivering methodologies and tools supporting the designer in the following issues.
Ontology and mapping development and maintenance. Developing and maintaining an OBDM specification is complex, and our goal is to develop the first comprehensive methodology and associated tools for this task. The objective is to support the designer in all relevant subtasks, namely, ontology and mapping bootstrapping, ontology and mapping engineering, OBDM debugging, OBDM transformation, and OBDM evolution. We plan to exploit existing techniques from ontology evolution [17], ontology matching [23], and mapping evolution [20], and develop our own novel techniques, in particular to cope with the new issues in ontology and mapping engineering that are crucial for open data, which we now discuss. Notably, the notion of mapping we will consider goes beyond the usual mappings from relational data to ontologies: we will indeed extend this notion and the associated language (in particular, R2RML), to NoSLQ data sources, in the spirit of [8].
Since open data represent information situated in space and time, one crucial issue is dealing with time-dependent and space-dependent aspects in ontology and mapping specification. This problem has been considered from different points of view in the last years [22,24], but a unified approach to modeling time and space using tractable ontology constructs, and to mapping data sources with time and space dimensions to ontologies is not yet available. Another crucial aspect is the possibility of modeling aggregate concepts at the ontology level, and mapping data at various levels of aggregation. The goal here is to revisit the work on modeling aggregation at the conceptual level, and develop solutions that can be smoothly integrated with modern ontology languages, ensuring good computational properties of reasoning about such enriched representation.
In our approach, modeling and mapping meta-concepts and meta-relations in the ontology, as well as modeling metadata associated to data sources and datasets is also extremely important. These aspects require new (second-order) constructs both in the ontology and the mapping languages [16], and new techniques for reasoning over ontologies and mappings, for which we will build on our recent results on reasoning about domain metamodeling in OWL and its fragments [21].
Dealing with privacy requirements. Taking privacy into consideration is important in any open data initiative, especially considering the fact that often open datasets have more value if they are released at the highest possible level of granularity, not in aggregate or modified forms. Such a level of release may, however, introduce the risk of exposing personally identifiable information, impacting the individuals’ privacy. The research community has dedicated many efforts to the design of (micro)data protection techniques, especially following the introduction of k-anonymity [31], and its extensions [30]. Recent approaches (e.g., differential privacy and its variations [28]) aim at providing semantic privacy guarantees defined by the data holder prior to data publication. All these approaches represent important advancements, but many issues remain, such as the need of generic privacy constraints/requirements used to verify whether data can be “safely” released, the need of maintaining the utility of the data after the application of privacy measures, and the need for metrics measuring privacy and privacy exposure of data collections.
Recent proposals have been focused on the specification of security and privacy models, policies, and mechanisms [27], but limited attention has been devoted to the problem of empowering the data owner to specify possible privacy restrictions, regulating secondary use or dissemination of information (e.g., P3P). With the adoption of cloud computing technologies, techniques for protecting data stored at external cloud providers outside the data owner control have been investigated [26,29]. Although the need of formalisms and tools for facilitating the specification of privacy requirements and for efficiently enforcing them is largely recognized, a practical solution for this problem is still missing. HOPE will define a flexible and extensible model and a declarative language able to capture privacy requirements on open data usage and sharing, secondary use, and information flow. Such requirements may come from different interplaying components as well as different parties (e.g., users, providers, legislators). Another important line of research is related to the definition of techniques for regulating access to data [25]. HOPE will design innovative solutions that will regulate access to heterogeneous data according to the profile of the requester, the provenance data, and metadata specifying security properties of the data themselves.
Automatic open data production. The investment on ontology and mapping specification pays off in several ways in the context of open data management. Arguably, a crucial one is enabling a methodology for automatic production of open datasets. Our goal in this respect is to design methods and tools for specifying the content of the datasets to publish, and producing each dataset in such a way that semantic annotations, provenance information and suitable metadata are automatically associated to it.
We will explore different strategies for declaratively specifying the content of a dataset. An obvious way to proceed to open data publication is to express the dataset to be published in terms of a SPARQL query over the ontology, to compute the certain answers to the query, and to publish the result of the certain answer computation, using the query expression and the ontology as a basis for annotating the dataset with suitable metadata expressing its semantics. We call such method top-down. Within such approach, our goal is to devise methods for automatically associating the “best” semantic annotations, and the “correct” metadata to the datasets, including information about the quality of the information it conveys, and the provenance of such information. We will take advantage both from the work done in the context of the “provenance” ontology, and from the recent result on reasoning about data quality using the OBDM paradigm [15]. Also, we will explore the relationship between provenance and explanation, in the spirit of [13], in order to derive annotations at a more fine-grained granularity, i.e., at the level of the single tuples rather than for the whole dataset. The top-down approach requires skills in many aspects (ontology language, SPARQL, etc.) and full awareness of the ontology. Unfortunately, in many organizations (for example, in Public Administrations) it may be the case that people are not ready to use the ontology and to base their tasks on it. Rather, the IT people might be more confident to express the specification of the dataset to be published directly in terms of the source structures (i.e., the relational tables in their databases), or, more generally, in terms of a view over the sources. To address this issue, an innovative, bottom-up approach will be studied: the organization expresses its publishing requirement as a query over the sources, and, by using the ontology and the mapping, a suitable algorithm induces the corresponding query over the ontology. In other words, we will synthesize the SPARQL query from a low-level specification over the sources, according to the first results reported in [14].
From the point of view of consumers, HOPE aims at providing features both for querying the open data collections, and for taking advantage of the enrichment of open data with social content.
Semantic query answering. There exists a rich literature on answering queries expressed over ontologies, by reasoning about the ontology and the mappings, and then reformulating the request into suitable queries to be executed over the data sources. We plan to build our service of semantic query answering by relying on, and extending, such techniques. We are in a privileged position to do so, since two of the world-leading semantic query answering systems (i.e., [10] and [12]) are developed and maintained by two partners of the consortium. Observe, though, that all the modeling challenges due to the novel complex components of an OBDM specification reflect into challenges at the level of semantic query answering. Some of these challenges have been partially addressed already, such as NoSQL data sources [8], and temporal aspects [9]. However, such investigations have been carried out in a standalone fashion, and not in a coherent and holistic context as the one being proposed within HOPE. Query answering over heterogeneous geospatial data, instead, requires a full integration of datasets and a proper consideration of their spatial (where), temporal (when), and thematic (what) components. A typical geospatial query such as "retrieve the number of car accidents in southern Italy in the last 10 years, when datasets are organized per region and per months" involves not only retrieving information spanning across different datasets, but also aggregating their values according to their spatial and temporal dimensions.
Friendly access to open data. One of the main barriers that impede the widespread use of open data is that access to the information of standard tools is difficult for experts and almost impossible for casual users. The well-known 5-star deployment scheme for Open Data, focusing on the publication formats and interoperability, does not address the usability issues. According to the Open Data Institute, "if we could build a query engine that's usable by all, that would be a real winner". An important goal of HOPE is to design advanced user-friendly interfaces simplifying the way users formulate queries, leading to easy tools that will hide both the tricky SPARQL syntax and the opaque schemas. To reach this challenging goal we will focus on three different research directions: natural language (question answering), visual interfaces (by-example structured querying), and hybrid solutions. Our plan is to leverage our record of successful approaches. By-example structured querying (BEStQ) [33, 34] allows to query DBpedia by transforming Wikipedia Infoboxes into simple forms in which the user can specify constraints in a familiar interface. This approach will be generalized in order to support any kind of open dataset, getting rid of the current need of Wikipedia infoboxes and instead automatically generating user friendly forms based on the open data. This will require the study and development of algorithms that can understand the importance of each dimension in the data [35] in order to keep these forms simple but complete. The use of natural language will be also investigated, in particular by extending the QA3 question answering system for statistical linked data developed by one of the partners of the consortium [36] to more general scenarios such as those in HOPE. We plan to substitute current expert-defined patterns in QA3 with automatically-generated templates by using machine learning techniques. Hybrid approaches will also be explored, in particular the use of natural language within a structured interface like BEStQ. We believe that for general-purpose applications, this can lead to a tool that maximizes end-user exploitation without making assumptions on schema and data, therefore maximizing data publisher flexibility.
Enriching open data with social content. Nowadays, the social reaction to content production is foremost relevant, as social media are becoming the predominant context of interpretation of events; thus, understanding and controlling the social relevance of open data is important. Such relevance is amplified by events that are typically outside of the control of the data publishing organization; for instance, open data about crimes gain social relevance when crime events capture social attention. For this reason, the enrichment of open data content starts with matching texts of news to open data descriptions, and then uses matching keywords for anchoring open data to the social communities that are mostly interested in those keywords. To this purpose, we will adapt syntactic methods that recently received attention, such as word embeddings [18]. The main challenge in open data enrichment lies in matching the knowledge expressed by open data with the interpretation of that knowledge in social media, e.g. by individual social accounts or given communities. Experiences in extracting emerging knowledge from social media [5] are an important starting point. Temporal and spatial aspects can be studied, e.g. along the methods used in [6,7], where a social response to a specific event (the Milano Fashion week) has been studied; the challenge in our research will be to trace how the social interpretation changes over time and space as effect of new events. An important aspect of social analysis will be to discover when social responses reveal conflicts with published open data - hinting to the possibility of factually erroneous or fake interpretations; completely unsupervised detection is difficult, but highlighting potential conflicts is instead feasible.
Methodology and organization of the project
The project aims at producing foundational research and demonstrators, through selected use cases. It features a mix of techniques lying at the border between data management and knowledge representation, and integrating several reasoning approaches, including deductive (e.g., query answering, reasoning on privacy) and inductive reasoning (e.g., extracting emerging knowledge from social media, question/answering). The scientific value of the results will be measured through publications in high-impact venues. From the point of view of practical applicability, we want to stress that the final result of the project will be a complete system integrating all the tools in a single, unified environment, leveraging on MASTRO-STUDIO [12], a technological platform already developed by the partners. The modular architecture of such system will allow, with the help of tools such as Github, the collaborative development and versioning of the code. The practical value of the whole approach will be evaluated by real users, including some of the crucial players in open data publishing in Italy.
The HOPE project puts together five partners including the strongest leaders of the Italian Knowledge Representation community and the Data Management community, featuring high international standing and visibility. UNIRM and UNIBZ are among the strongest groups in Ontology Languages and Reasoning worldwide, POLIMI and UNIMI are leading groups in Data Management, and on security and privacy, and the group of UNICA, although young, has already a high international reputation in the Semantic Web and the Data Mining communities. The project team includes 6 among the first 20 (and 4 members among the first 7) Italian Computer Scientists with the highest H-index, according to [37]. The groups have a strong experience of mutual collaboration. For example, UNIRM and UNIBZ jointly pioneered the OBDM paradigm, UNIRM and POLIMI worked together in a project on bioinformatics, in particular for exploiting ontological knowledge in querying genomic data, UNIMI and UNIRM have jointly addressed the problem of specifying authorization views over ontologies, and POLIMI and UNICA have an ongoing collaboration on information extraction from social media. The net funding obtained will allow for opening up a total of 16 new junior positions at the PhD/PostDoc level. The partner universities will provide co-financing of ~10% of the project budget through their own employed researchers. This will be topped up by a significant in-kind contribution of the employed researchers, including guidance to the new PhDs/PostDocs.
3. Project development, with identification of the role of each research unit with regards to expected targets, and related modalities of integration and collaboration
Overview
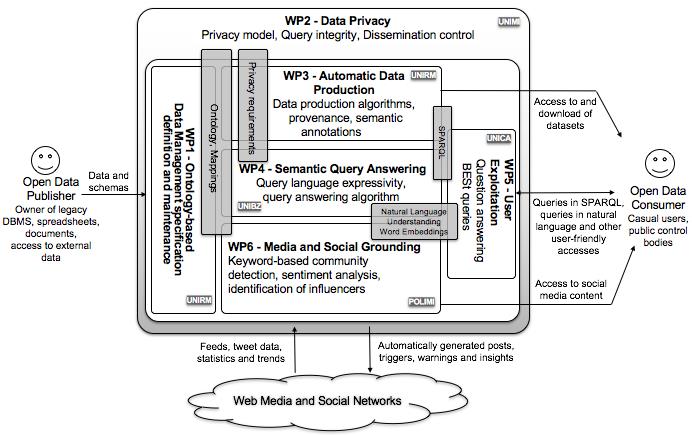
The development of the project is based on 7 workpackages (WP), each addressing one of the challenges illustrated in Section 2, and lasting for all the duration of the project. All techniques developed in the WPs will be implemented as plug-ins of MASTRO-STUDIO, and the collaboration needed for this objective is carried out in WP7. In the illustration of WPs, we will not explicitly indicate such implementation effort. The figure above shows how WP1-WP6 fit in the general framework of HOPE, and indicates the units that are responsible for each WP, together with the main topics of collaboration (grey boxes).
WP1 - Ontology and mapping development and maintenance (effort in M/M: 70)
Unit Leader: UNIRM [collaboration with: UNIMI, POLIMI, UNIBZ]
Scientific Responsible: Gianluca Cima
We design methodology and tools for setting up and maintaining an OBDM specification for open data management, in collaboration with UNIMI for privacy issues.
Ontology modeling. We study extensions of the ontology languages for representing provenance, time, metaclasses, metadata and quality characteristics of data sources, and aggregated concepts. POLIMI collaborates in the definition of the new modeling structures, so that they can be effectively used in the activities related to WP6.
Mapping specification. We study extensions of the mapping language in order to map metadata, quality and provenance information, as well as time-dependent data to the corresponding primitives at the ontology level. We study techniques for the corresponding mapping analysis tasks. For all languages considered, we devise solutions representing an optimal compromise between expressive power and computational complexity of reasoning. UNIBZ participates with the goal of making sure that the new language constructs can be efficiently processed during query answering.
Deliverables. Methodology for developing and maintaining an OBDM specification for open data management (first report at M12). Tools supporting the methodology (final report on methodology and report on tools at M36).
WP2 - Data privacy (70)
Unit Leader: UNIMI [UNIBZ, UNIRM]
Scientific Responsible: Sabrina De Capitani di Vimercati
We study mechanisms for the formal specification of privacy requirements and for supporting the privacy-aware release of open data.
Privacy specification language. We define the specification language and its formal semantics, taking into account the privacy requirements coming from legislation, the contextual information, and the need of declaratively identifying the portions of data that can be accessed. The language will also consider provenance information for data, and the process tracking for assessing metadata about quality and trust.
Privacy-aware open data release. We study scalable and efficient techniques for evaluating whether and how possible sensitive datasets could be released without violating the requirements, and for suggesting possible data sanitization and obfuscation that would make the release “safe”.
Query integrity and dissemination control. We design solutions for ensuring the integrity of queries so that the data owner can tune the amount of controls to be enforced, and therefore the privacy guarantees to enjoy and the performance overhead to pay, depending on different contexts or applications.
Deliverables. Languages for privacy requirements specification (M12). Techniques for query integrity and provenance (M24). Tools for enforcing privacy requirements and for dissemination control (M36).
WP3 - Automatic open data production (65)
Unit Leader: UNIRM [UNIBZ, UNIMI]
Scientific Responsible: Gianluca Cima
We design algorithms and develop tools for supporting the designer in the specification of the content of the datasets to publish, so that they can be produced with all relevant semantic annotations.
Top-down methods. We develop methods that, given a SPARQL query over the ontology, automatically synthesize a process that extracts the content of the dataset from the sources, associating to it suitable semantic annotations and metadata. We study approximation techniques in case of worst-case intractability.
Bottom-up methods. Bottom-up methods are used when the organization expresses its publishing requirement as a query over the sources, and the goal is to induce the corresponding query over the ontology (reverse rewriting). Since it may happen that the “best” reverse rewriting does not exist, we study techniques that allow us to compute the best approximation, both in the case of sound (all answers computed by the reverse rewritings are correct) and in the case of complete (no answer of the original query is missed) rewriting.
Deliverables. Open data production methods: algorithms and complexity (M12). Open data production methods coherent with privacy requirements (M24). Integration of tools into the HOPE suite (M36).
WP4 - Semantic query answering (75)
Unit Leader: UNIBZ [UNIRM, UNIMI, UNICA]
Scientific Responsible: Diego Calvanese
We deal with semantic query answering over open data, focusing on the many challenges arising from the enriched expressiveness of an OBDM specification.
NoSQL Data Sources. We study how to extend semantic query answering to the case of NoSQL data sources. This requires to reconcile the mismatch between SPARQL and NoSQL-specific query languages, trying to make use of pre-computed joins. A related, and challenging, direction is how to handle efficiently nested data. To deal with different formats of source data, we plan to rely on data federation middleware.
Temporal and Geospatial Data. Temporal and geospatial queries in OBDM require a careful balance between expressivity and efficiency. We deal with geospatial queries, and translate them in a way that is compatible with geospatial databases. To deal with temporal data, we study ontology language extensions with temporal modeling features, and adapt query transformation techniques to this richer setting.
Queries with Aggregation. Aggregating query results is a fundamental capability not yet formalized for OBDM. Two key challenges are robustness to redundancy, and dealing with heterogeneous datatypes. We study formal semantics and algorithms to address these problems.
Deliverables. Access to NoSQL, temporal data, and geospatial data (M12). Aggregates and meta level information (M24). Querying of multiple data sources in a combined way (M36).
WP5 - User exploitation (70)
Unit Leader: UNICA [UNIBZ, POLIMI]
Scientific Responsible: Maurizio Atzori
We study innovative querying interfaces to provide user-friendly access to the underlying open data.
Question Answering. We study question/answering interfaces, where the user will interact through natural language, by generalizing our state-of-the-art datacube-querying system (QA3). We base our solutions on automatically learning the sparql sub-patterns that are currently handcrafted. We address scalability issues by introducing the use of word embeddings, realizing a general multilingual tool converting natural language questions into sparql queries.
By-Example Structured Query. We extend our By-Example Structured Query (BEStQ) approach to general open datasets. Set expansion techniques will be used to simplify the choice of an initial example and automatically disambiguate toward different interpretation, by intersecting different constraints available from the ontology. We investigate hybrid approaches, in order to minimize user burden and maximize precision, recall and user satisfaction. We collaborate with UNIBZ for query oriented issues, and with POLIMI on application of natural languages approaches over media and social data.
Deliverables. Algorithms for general Q/A and BEStQ (first report M12, second report M24). Tools supporting the developed approaches (M36).
WP6 – Media and Social Grounding (72)
Unit Leader: POLIMI [UNICA, UNIRM]
Scientific Responsible: Stefano Ceri
Our goal is identifying the media sources and social accounts producing content related to specific open datasets, and then studying the nature of the interactions between social players.
Matching. We study methods for matching the textual descriptions of open data against news about them, using similarity search based on word embedding; news can be selected based on time (e.g. news at a given date) or source (i.e.TV or newspaper channel); methods based on word embeddings for matching texts will be jointly developed with UNICA. The obtained corpus is then used to extract social accounts, using classic keyword-based search on Twitter. These social accounts are considered as a community whose observed aspects include: profile analysis, demographics, sentiment analysis, identification of influencers.
Social relevance. We study methods for understanding the social relevance and impact of the published data through quantitative and qualitative predictions. Sources which discuss published datasets could be candidates for fact checking and fake news discovery. We study techniques for selectively pushing open data to specific users or networks based on matching interests.
Deliverables. Methodology for linking open data to media and to a social network that reacts to media publishing (first report M12). Tools supporting the social network extraction and for predicting the impact of data publishing (final report on methodology and report on tools M36).
WP7 - Coordination, deployment and use cases (45)
Unit Leader: UNIRM [POLIMI, UNIBZ, UNICA, UNIMI]
Responsible: Maurizio Lenzerini; Gianluca Cima
General coordination. The coordinator will lead the coordination task, and will organize three plenary project meetings.
Tool integration and deployment. All the techniques developed in the WPs will be implemented and incorporated as plug-ins of the MASTRO-STUDIO system, of which all partners have already a good knowledge.
Use cases. UNIRM will lead the joint work with both ISTAT and ACI Informatica, whereas UNIBZ will lead the interaction with IDM. The work on the OBDM specification will be carried out jointly with UNIMI. UNICA and POLIMI will experiment their techniques in all the three use cases starting from M7.
Deliverables. Yearly progress reports (M12, M24), and the final project report (M36), including the descriptions of the use cases.
4. Possibile application potentialities and scientific and/or technological and/or social and/or economic impact of the project
The potential scientific impact is on several aspects of data management. HOPES will be the first comprehensive system for specifying and maintaining an OBDM specification for open data, incorporating methods for ensuring the conformance of all its services to the specified privacy requirements, thus following the “privacy by design” philosophy. HOPES will extend the ontology and mapping languages used in current OBDM approaches, in particular to capture time and space dimensions, and to express aggregate concepts and provenance, which are crucial in open data. New features for reasoning about queries and mappings, and new notions of query rewriting will provide crucial services for the automatic publication of semantically annotated data. HOPES will enrich the query capabilities of current OBDM systems. Based on them, the system will provide new user friendly mechanisms for querying open data, an aspect that seems completely overlooked in current solutions. Novel methods will help identifying the social media sources producing content related to specific open datasets, thus enabling situating the open datasets in the social context.
The distinguished feature of HOPE is that all the above advances will represent a body of knowledge geared towards the goal of achieving a new way to manage and exploiting open data. The main result of the project will be a concrete open data management system that organizations can use in order to support the governance of its data sources and the production of semantically annotated open data. Our ambitious goal is to make HOPES the main force towards the solution of the technological impediments for a more satisfactory diffusion of open data. If successful, this effort will have a deep impact on society, as it will help unchaining all the potentiality of open data in the data-driven society. The practical value of the whole approach will be evaluated by real users, including some of the crucial players in open data publishing in Italy. Three Italian PA institutions are already collaborating with the partners of the consortium, and have agreed to experiment the tools resulting from the new research results. We will greatly benefit from their feedbacks from the very beginning of the project.
Istat, the Italian National Institute of Statistics, is the main producer of Official Statistics in Italy. In an ongoing collaboration with UNIRM, ISTAT has already produced the ontology and the mapping for all the concepts relevant for the national census. ISTAT has agreed to experiment HOPES in all the issues related to both maintaining the ontology and the mappings, and producing semantic open data within this domain. The responsible of the collaboration will be Monica Scannapieco.
While ISTAT is an example of central PA in Italy dealing in principle with all aspects of society, ACI Informatica, the in-house IT company of ACI - Automobile Club of Italy, is an example of focused PA, dealing in particular with all aspects of mobility at the national level. The ongoing collaboration with UNIRM has the goal of integrating all national data sources regarding the register of vehicles and their taxation, ACI recently started a new project for setting up an open data portal over mobility-related, and they agreed to design and develop such portal following the principle, the guidelines and the tools provided by HOPE. The responsible will be Mario Punchina.
As for local PA, IDM is a company owned by the Autonomous Province of Bolzano and the Bolzano Chamber of Commerce that promotes the regional development and provides services to local companies. IDM is currently collaborating with UNIBZ on assessing the status of open data in South Tyrol, and where interventions are necessary to improve data usability. IDM plans to realize a platform for providing integrated access to open data that is relevant for the local economy, and towards this objective it agreed to exploit the methodology developed in HOPE, and to build on the HOPES platform. The responsible will be Stefano Seppi.
All the above partners have also expressed great interest in privacy-preserving solutions that allow them publishing more elementary data, instead of only aggregated data, and in the possibility of providing means for enhanced user exploitation, including both links with social media, and user-friendly query endpoints going beyond the current solutions that are hardly used by consumers. Notably, there is a perfect match between these demands and the themes studied in HOPE.
In order to attract other users, we will create and maintain a project website, to enhance the HOPE visibility and disseminate its results. We plan to organize specific workshops after the first year of the project, and one final workshop on the problem of producing and consuming semantic open data, preferably in the context of the FORUM PA, which is the annual Italian forum of Public Administration.
5. Bibliography
[1] The 2107 Landscaping report of the European Open Data Portal, www.europeandataportal.eu.
[2] The 2017 Survey on Open Data by the Italian government, www.dati.gov.it.
[3] The 2017 Global Report of Open Data Barometer, www.opendatabarometer.org.
[4] N. Antonioli, et al: Ontology-based Data Management for the Italian Public Debt. FOIS 2014: 372-385.
[5] M. Brambilla, S. Ceri, E. Della Valle, R. Volonterio, F. Xavier Acero Salazar: Extracting Emerging Knowledge from Social Media. WWW 2017: 795-804.
[6] M. Brambilla, S. Ceri, F. Daniel, G. Donetti: Spatial Analysis of Social Media Response to Live Events: The Case of the Milano Fashion Week. WWW (Companion Volume) 2017: 1457-1462.
[7] M. Brambilla, S. Ceri, F. Daniel, G. Donetti: Temporal Analysis of Social Media Response to Live Events: The Milano Fashion Week. ICWE 2017: 134-150.
[8] E. Botoeva, et al: OBDA Beyond Relational DBs: A Study for MongoDB. Description Logics 2016.
[9] Sebastian Brandt, et al.: Ontology-Based Data Access with a Horn Fragment of Metric Temporal Logic. AAAI 2017: 1070-1076.
[10] D. Calvanese, B. Cogrel, S. Komla-Ebri, R. Kontchakov, D. Lanti, M. Rezk, M. Rodriguez-Muro, G. Xiao: Ontop: Answering SPARQL queries over relational databases. Semantic Web 8(3): 471-487 (2017).
[11] D. Calvanese, G. De Giacomo, D. Lembo, M. Lenzerini, R, Rosati: Tractable Reasoning and Efficient Query Answering in Description Logics: The DL-Lite Family. J. Autom. Reasoning 39(3): 385-429 (2007).
[12] Cristina Civili, et al: MASTRO-STUDIO: Managing Ontology-Based Data Access applications. PVLDB 6(12): 1314-1317 (2013).
[13] D. Calvanese, M. Ortiz, M. Simkus, G. Stefanoni: Reasoning about Explanations for Negative Query Answers in DL-Lite. J. Artif. Intell. Res. 48: 635-669 (2013).
[14] G. Cima: Preliminary Results on Ontology-based Open Data Publishing. Description Logics 2017.
[15] M. Console, M. Lenzerini: Data Quality in Ontology-based Data Access: The Case of Consistency. AAAI 2014: 1020-1026.
[16] F. Di Pinto, G. De Giacomo, M. Lenzerini, R. Rosati: Ontology-Based Data Access with Dynamic TBoxes in DL-Lite. AAAI 2012.
[17] Grau, B.C., et al: Ontology Evolution Under Semantic Constraints. In: KR 2012 (2012).
[18] M. J. Kusner, Y Sun, N. I. Kolkin, K. Q. Weinberger: From Word Embeddings To Document Distances. ICML 2015: 957-966.
[19] M. Lenzerini: Ontology-based data management. CIKM 2011: 5-6.
[20] D. Lembo, R. Rosati, V. Santarelli, D. F. Savo, E. Thorstensen: Mapping Repair in Ontology-based Data Access Evolving Systems. IJCAI 2017: 1160-1166.
[21] M. Lenzerini, L. Lepore, A. Poggi: Answering Metaqueries over Hi (OWL 2 QL) Ontologies. IJCAI 2016: 1174-1180.
[22] T. Podobnikar and M. Čeh.: Universal Ontology of Geographic Space: Semantic Enrichment for Spatial Data. IGI GLOBAL, 2012.
[23] Jimenez-Ruiz, E., Grau, B.C.: LogMap: Logic-Based and Scalable Ontology Matching. In: International Semantic Web Conference (1). pp. 273–288 (2011).
[24] Time Ontology in OWL. https://www.w3.org/TR/owl-time/, W3C Recommendation, 2017.
[25] E. Bacis, S. De Capitani di Vimercati, et al, "Mix&Slice: Efficient Access Revocation in the Cloud," in Proc. of CCS 2016, Vienna, Austria, October 2016.
[26] A. Bergmayr, U. Breitenbücher, N. Ferry, A. Rossini, A. Solberg, M. Wimmer, G. Kappel, F. Leymann, "A Systematic Review of Cloud Modeling Languages", in ACM Computing Surveys, vol. 51, n. 1, February 2018.
[27] P. Bonatti, P. Samarati, "Logics for Authorizations and Security," in Logics for Emerging Applications of Databases, J. Chomicki, R. van der Meyden, G. Saake (eds.), Springer-Verlag, 2003.
[28] C. Dwork, "Differential Privacy," In Proc. of ICALP 2006, Venice, Italy, July 2006.
[29] S. De Capitani di Vimercati, et al, "An Authorization Model for Multi-Provider Queries," in Proc. of the VLDB Endowment, vol. 11, n. 3, November 2017.
[30] B.C.M. Fung, K. Wang, R. Chen, P.S. Yu, "Privacy-Preserving Data Publishing: A Survey of Recent Developments, " in ACM Computing Surveys (CSUR) Surveys, vol. 42, n. 4, June 2010.
[31] P. Samarati, "Protecting Respondents' Identities in Microdata Release," in IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 13, n. 6, November/December 2001.
[32] M. Beno, K. Figl, J. Umbrich, A. Polleres. Open Data Hopes and Fears: Determining the Barriers of Open Data. IEEE Explore. DOI: 10.1109/CeDEM.2017.22, 2017.
[33] M. Atzori, S. Gao, G. M. Mazzeo, C. Zaniolo. Answering End-User Questions, Queries and Searches on Wikipedia and its History. IEEE Data Engineering Bulletin 39(3): 85-96 (2016).
[34] C. Zaniolo, S. Gao, M. Atzori, M. Chen, J. Gu. User-friendly temporal queries on historical knowledge bases. Information and Computation, Elsevier, 259(Part): 444-459 (2018).
[35] A. Dessi, M. Atzori. A machine-learning approach to ranking RDF properties. Future Generation Computer Systems, Elsevier, 54: 366-377 (2016).
[36] M. Atzori, G. M. Mazzeo, C. Zaniolo. QA3: a Natural Language Approach to Question Answering over RDF Data Cubes. Semantic Web Journal, to appear.
[37] www.topitalianscientists.org/TIS_HTML/Top_Italian_Scientists_Computer_Sciences.htm.
[38] www.datiopen.it/it/opendata/Regione_Veneto_Laureati_per_universit_facolta_e_anno.